Implementing Lempel-Ziv Jaccard Distance (LZJD) in Rust

One of our clients helps companies in becoming GDPR-compliant. A goal is to recognize sensitive pieces of user data in a big pile of registrations, receipts, emails, and transcripts, and mark them to be checked out later. As more and more data is collected by companies, finding and eliminating sensitive data becomes harder and harder, to the point where it is no longer possible for mere human employees to keep up without assistance.
A crate I’ve been working on, LZJD-rs, implements an algorithm that can be used to automate this process. It is my first serious attempt at an open source contribution in Rust, and an interesting one at that.
LZJD
To detect similar documents containing sensitive information, one can use the Lempel-Ziv Jaccard Distance or LZJD algorithm proposed by Edward Raff and Charles Nicholas [1]. LZJD is a means of calculating edit distance between binary sequences. It is based on Normalized Compression Distance (NCD), which is used in malware classification software. NCD essentially is quite a simple algorithm. In NCD, two binary sequences are first compressed apart from each other. The total of the sizes of the compressed sequences is then compared to the size of the compression output of the two binary sequences concatenated. As compression eliminates duplications in sequences, the greater the difference between the compared sizes, the more the two sequences were alike.
A significant portion of the work being done in NCD, like substituting parts of the sequence and writing the compressed file, can be eliminated by simply comparing the size of the substitution dictionaries. LZJD does exactly that, significantly improving the calculation speed. What’s more, LZJD only compares a small portion of the dictionaries in order to speed up the process even more. The steps taken by the algorithm in order to compare two binary sequences are roughly the following:
- Generate a Lempel-Ziv dictionary for each of the sequences;
- Generate a hash of each of the entries in both dictionaries;
- Sort the hashes and keep only the k=1024 smallest;
- Calculate the Jaccard distance between both of the lists of smallest hashes.
This rather simple approach could enable scaling classification processes significantly [2].
A Rust implementation
Raff and Nicholas provided a reference implementation, jLZJD, written in Java. jLZJD’s interface is a lot like that of the well-known classification tool sdhash. Given that our client has written their entire application in Rust, they asked us to create an open-source Rust implementation of LZJD: LZJD-rs.
My initial implementation of LZJD-rs and jLZJD did not only differ in programming language. To optimize the architecture a bit, I introduced implementation differences as well. For instance, jLZJD uses a simplified hash set to store dictionary entry hashes in, called IntSetNoRemove. After processing the sequence, the entries in the hash set are sorted and truncated to the desired length for comparison.
In contrast, LZJD-rs’ first version used a fixed-length vector in which the entries are inserted in such a way that the result is always an ordered list that can be compared immediately. To keep the entries sorted, a binary search is performed to find the spot in which a hash should be inserted. This way, no unnecessary allocations are done to retain data that will be thrown away later.
pub fn from_bytes_stream<I, H>(seq_iter: I, build_hasher: &H, k: usize) -> Self
where
I: Iterator<Item = u8>,
H: BuildHasher,
{
let mut entries = Vec::with_capacity(k);
let mut hasher = build_hasher.build_hasher();
seq_iter.for_each(|byte| {
// Update hash
hasher.write_u8(byte);
let hash = hasher.finish();
if let Err(insert_at) = entries.binary_search(&hash) {
// If entries does not yet contain current hash
if entries.len() < k {
// There's room for another hash without reallocating
entries.insert(insert_at, hash); // Insert current hash
hasher = build_hasher.build_hasher(); // Reset hasher
} else if hash < *entries.last().unwrap() {
// Current hash is smaller than largest in entries
entries.pop(); // Remove greatest hash
entries.insert(insert_at, hash); // Insert current hash
hasher = build_hasher.build_hasher(); // Reset hasher
}
}
// else it's already in there and we can go on
});
LZDict { entries }
}
Quite proud of the optimization I added, I asked Edward Raff to review my code. He responded with an observation: alas, my optimization was incorrect. Truncating the dictionary in-process makes the application forget about certain sequences, which will be treated as new, even when they are not. Thank you for the feedback, Edward!
Me and my colleague Ruben started working on a new implementation, more similar to jLZJD. Like jLZJD, it uses a hash set internally to store dictionary entry hashes in: std::collections::HashSet. After processing the sequence, the entries in the hash set are sorted and truncated to the desired length for comparison. jLZJD uses the MurmurHash3 algorithm to hash dictionary entries, whereas LZJD-rs library is designed to use any hashing algorithm. The binary however, like jLZJD, uses the MurmurHash3 algorithm.
pub fn from_bytes_stream<I, H>(seq_iter: I, build_hasher: &H) -> Self
where
I: Iterator<Item=u8>,
H: BuildHasher,
{
let mut dict = HashSet::new();
let mut hasher = build_hasher.build_hasher();
for byte in seq_iter {
hasher.write_u8(byte);
let hash = hasher.finish() as i32;
if dict.insert(hash) {
hasher = build_hasher.build_hasher();
}
}
let mut dict: Vec<_> = dict.iter().cloned().collect();
dict.sort();
LZDict { entries: dict.iter().cloned().take(1000).collect() }
}
Putting it to the test
One of the goals of Rust is optimizing efficiency. LZJD-rs being written in Rust, would it be faster than jLZJD? Well, let’s have a go at benchmarking both implementations. Initially, I created a basic test environment in which both implementations compare two 200MB random files, using a single thread to compute the LZ-dictionaries. LZJD-rs did it in a whopping 72 seconds on average on my machine. However, jLZJD, to my surprise, did it in about 38 seconds on average. That’s almost twice as fast!
Not as easy as I thought it would be. To find out what was the cause of my implementation being slow, I used a profiling tool called Perf. Perf uses hardware and operating systems counters to mark so-called hot spots in compiled programs, so that optimization can be focused on the parts where the biggest potential gains lie. Below is a screenshot of the hottest spots found in LZJD-rs:
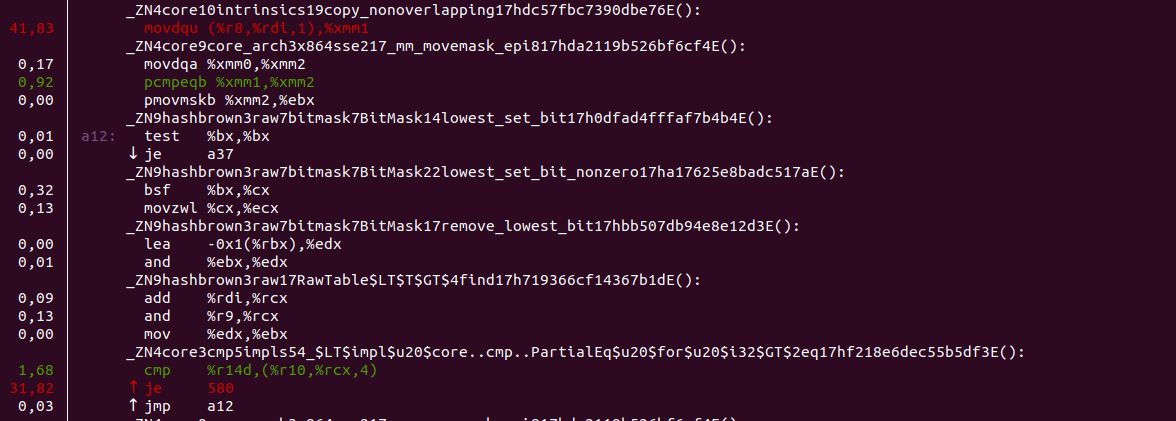
The lines in white, starting with _ZN, are the mangled names of the functions to which the instructions below them belong. Both red colored instructions are inside Rust’s std::collections::HashSet implementation. It would seem that mimicking jLZJD’s IntSetNoRemove in LZJS-rs or providing another more tailor-made HashSet implementation could benefit the performance LZJS-rs.
Future work
LZJD-rs is published on Crates.io and GitHub. I’ve been thinking about implementing a simple linear-probing hash set similar to IntSetNoRemove in order to improve performance.
It would be a valuable learning experience if other developers propose optimizations. Create a pull request on GitHub and I’d be happy to review it!
Citations
[1] Raff, E., & Nicholas, C. K. (2017). An Alternative to NCD for Large Sequences, Lempel-Ziv Jaccard Distance. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. http://doi.org/10.1145/3097983.3098111
[2] LZJD was considered by the Dutch government for classification purposes as part of their Di-Stroy program, see https://www.linkedin.com/posts/activity-6547029450402476033-i3AJ/ (Dutch)