
The point of setting up a miniservice architecture is to enable horizontal scaling, improve reusability and to speed up development by separating each domain into an independent application. Miniservices depending on a database pose a number of challenges. We'll explore a couple of them.
The point of setting up a miniservice architecture is to enable horizontal scaling, improve reusability and to speed up development by separating each domain into an independent application. Miniservices depending on a database pose a number of challenges. We'll explore a couple of them.
How to keep data consistent in a distributed system, keeping the system scalable and its domains separated? And how well does the traditional monolithic relational database do in terms of scalability and separation of concerns?
This article is the last part in a series of three, the first being 'From monolith to miniservices', the second 'Transitioning to a miniservice architecture'
Upsides of monolithic databases
Monolithic relational databases are popular and established systems that are well supported by many programming languages and frameworks. By defining relationships within the database system, keeping data consistent is relatively straightforward. Easily coupling related entity records is one of the strengths of the relational database.
Relational databases support ACID transactions, which guarantee data validity in flows where multiple entities need to be updated in an atomic way. In the event of a failure, ACID transactions can be rolled back entirely, keeping the database state consistent.
Keeping all data in the same place simplifies management. There is no need for knowledge of multiple database management systems.
Downsides of monolithic databases
Horizontally scaling monolithic databases is hard. Horizontal scaling of monolithic relational databases is usually set up using a master-slave replication model. In this model, the single master server handles all write transactions and propagates state updates to multiple slave servers. Read transactions are handled by the slave. The master-slave model does enable handling more read transactions, but write transactions are not scaled up.
An alternative replication model is the asynchronous multi-master model. The multi-master model allows for distributing read, as well as write transactions, over multiple servers. Keeping data consistent in this model is relatively challenging and ACID transactions are not supported. Inconsistencies cannot be prevented, but have to be resolved afterwards in order to gain an eventual consistent state.
Another possibility to scale traditional monolithic database systems is horizontal sharding, where each table is horizontally partitioned and distributed over many database servers. This increases the number of read transactions as well as the number of write transactions that can be handled. In this setup, a database server failing causes a whole table to become unavailable or at least incomplete if no complex failover system is used.
Monolithic databases are used for many tasks at the same time. Some tasks require joining data, some reading many rows and some require a lot of writes. The data being stored might not adhere to any structure. General-purpose databases by definition are not optimized for handling any single task.
Challenges with monolithic databases in miniservice architectures
Using a monolithic relational database as a single source of truth within a miniservice architecture introduces another set of challenges. Enforcing parts in the distributed system to only modify data within their domain is one of them. Failing to separate the data into separate domains can cause bugs in systems where services work asynchronously to each other.
Executing database migrations concurrently isn't easy either. Especially when different services are maintained by different software development teams, concurrent migrations have to be done very carefully and are error-prone.
Also, database migrations tend to introduce downtime of the database management system, especially when a large amount of data is to be manipulated. This would disable every miniservice that depends on the database, even though they run independently from each other.
Setup
But how to set up persistent miniservices elegantly? There's no single one-size-fits-all solution for this. Depending on the project context, different strategies of keeping data persistent within a miniservice architecture may be preferred. Roughly, these strategies are the following:
- Single database schema for many services. This strategy makes joins and data consistency easy, but the extensive dependency of data in relational databases causes updates across the whole system to become hard.
- One schema per service Restricts table access to a single service, keeping domains separated, but does not require setting up multiple databases. Cross-domain joining data becomes harder. This might be either a good or a bad thing, depending on the context.
- One database per service allows for choosing job-specific database management systems and separate development teams using different configurations. This is harder to set up, but enables all the good things miniservice architectures have to offer.
Eventual consistency
In practice, when data is separated in domains over many database servers, atomic transactions are not possible without extensive locking. There might not even be a consistent state at all times. Instead of using ACID transactions and locking, a mechanism should be introduced to gain an eventually consistent state. One interesting way to do this is by implementing the event sourcing pattern. In this pattern, all database mutations are stored in an event store, which publishes them to the system. The events should contain all information for an antagonist event to be created in case its effects need to be undone. Services in the distributed system can subscribe to these events and act accordingly. Whenever a series of events needs to be rolled back, antagonist events are emitted, stored, and handled to regain consistency.
|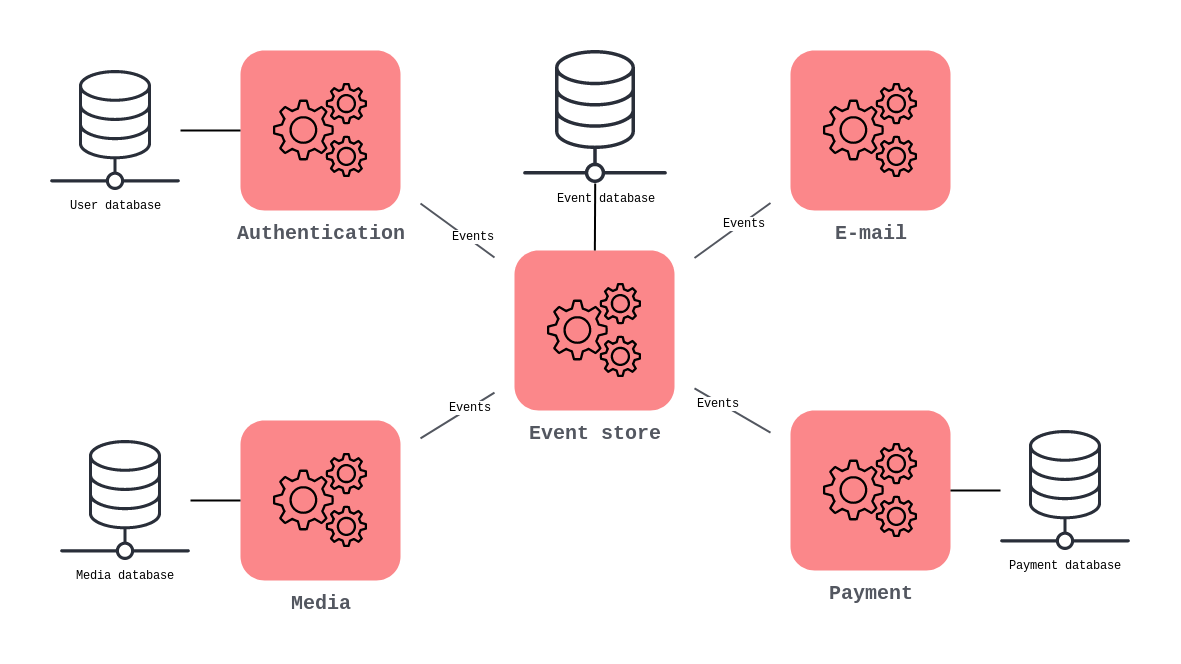 | An example of a system implementing the event sourcing pattern. The miniservices communicate via the central event store, which keeps record of each mutation in the system. The event store propagates the events received from a service to subscribers. Every event being saved, transactions can be rolled back if necessary. |
| An example of a system implementing the event sourcing pattern. The miniservices communicate via the central event store, which keeps record of each mutation in the system. The event store propagates the events received from a service to subscribers. Every event being saved, transactions can be rolled back if necessary. |
Using the event sourcing pattern, services can easily send status updates to their clients even before all parts in the transaction have been executed, notifying them of anything interesting happening in the process.
Conclusion
Setting up a system consisting of miniservices that depends on persistent state, is not an easy task. As your application becomes larger and more complex, moving from a monolithic database to a set of separated data sources, becomes a necessity. Depending on the project, one can go as far as they want with that. If you do choose to have each service maintain their own data, a good way of keeping your data consistent is by introducing the event store pattern. Although introducing overhead and complexity, it helps keeping concerns separated.
As Tweede golf is moving it's applications to use the miniservices in a service-oriented architecture setting, we won't be using the event sourcing pattern just yet, and we'll go for the simpler one-schema-per-service option. But you never know, maybe some time in the future the event sourcing pattern might be of use!
Once we have more experience on deploying complex miniservice architectures, we'll take another look at this exploration series.