Building an Async Runtime with mio
The example code in this blog comes from nea, a webserver that never allocates. Because of that, this web server is both fast and predictable.
Scheduling and executing async tasks is a job handled by an async runtime, such as tokio, async-std, and smol. You’ve probably used them at some point, either directly or indirectly. They, along with many frameworks that require async, do their best to hide the complicated details from the user as much as possible. However, as soon as you need to write your own Future for whatever reason, all the complicated details of async Rust start creeping in.
Many blog posts aim to explain async's complicated parts (looking at you, Pin) individually, so we won’t be repeating that here. Instead, we want to walk you through the steps to create your own async runtime, including a reactor that responds to OS events. Hopefully, this will give a more solid understanding of what happens behind the scenes, and help with future Future writing.
The source code of this project can be found on our GitHub.
Overview
An async runtime consists of two main components:
- The executor, essentially is a queue of futures that need to be executed by a background thread.
- A reactor, in effect a background thread that listens for certain OS events, for instance, a
TcpStreambecoming readable. When a future cannot make progress, it can ask the reactor to enqueue it again when a specific event occurs.
Two additional abstractions that are important are:
- The
Spawnercan insert new futures into the executor's queue. - A
Wakeris a callback that inserts an existing future back into the executor's queue.
The runtime that we’ll be building prioritizes understandability over performance, so some design choices may differ from those made in production runtimes. This schematic shows the execution flow of a single future:
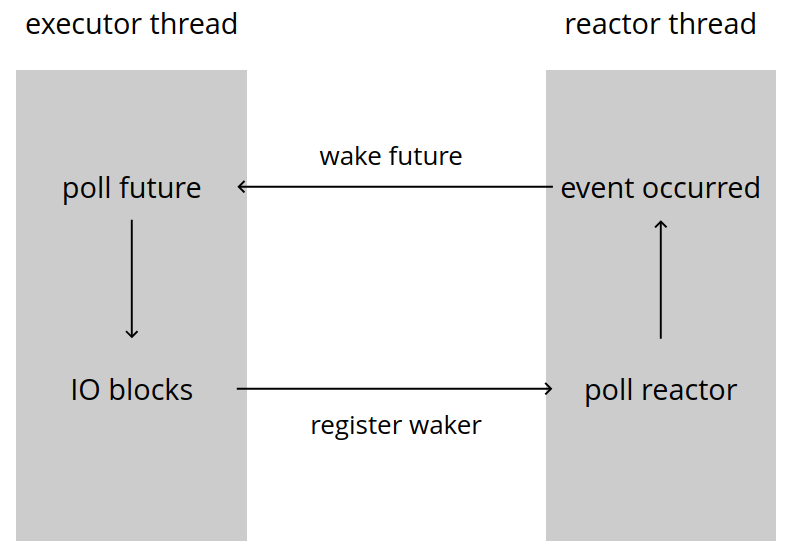
The main thread runs the Executor. In this example the executor thread performs the actual polling of the future. When a future hits a blocking IO operation, it registers a Waker with the reactor. This is effectively a callback that enqueues the future again.
The reactor then waits for the OS to signal that the IO action has been unblocked and wakes the future. At some point, the main thread will then pick this future up again and is likely to make further progress.
Implementing the Executor
First up is the executor. As mentioned this is essentially a queue of futures that the user program wants to run. The executor should poll these futures, but that is not straightforward because the signature of poll is quite tricky:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
Given a future, how to call poll on that future is not really immediately clear. The executor needs to have a specific shape to make it possible.
When writing an executor, the futures it deals with (which are usually the futures returned by main and any that are spawned with e.g. tokio::spawn) are called tasks. In our example, a task is represented as:
pub(crate) struct Task {
future: Mutex<Pin<Box<dyn Future<Output = ()> + Send + 'static>>>,
}
That is a lot of wrapping, but all the layers serve a role in being able to call poll on the contained future: The mutex provides the mutable reference, and the Box allows for the Pin wrapper that is needed.
A queue of tasks
An executor is a queue of tasks, so we need some queue implementation. For our example we are using an mpsc channel. This is just for simplicity: in practice you want multiple consumers so that your runtime can use multiple threads to perform work in parallel.
The executor is just the receiving end of an mpsc channel:
pub struct Executor {
ready_queue: std::sync::mpsc::Receiver<Arc<Task>>,
}
The corresponding mpsc::SyncSenders can be moved to different threads, and enqueue new tasks.
Note that we receive Arc<Task>s, rather than just Tasks. This is not the most performant option - heap allocation is not free - but it is convenient for our example because it simplifies the implementation of the waker later on.
Running the executor
For the executor to actually execute its tasks, we’ll define a run method:
impl Executor {
pub fn run(&self) {
while let Ok(task) = self.ready_queue.recv() {
let mut future = task.future.lock().unwrap();
// make a context (explained later)
let waker = Arc::clone(&task).waker();
let mut context = Context::from_waker(&waker);
// Allow the future some CPU time to make progress
let _ = future.as_mut().poll(&mut context);
}
}
}
The run method perpetually takes futures from its ready_queue, and calls their poll method so they can (hopefully) make progress. Note that poll requires a mutable reference to the future, because making progress will change its inner state machine. This is where the interior mutability of the Mutex comes into play. So long as there is only one instance of run at a time, the synchronization aspects of Mutex are not necessary here.
This executor is basic, but is now functional. There are just 2 things left to do:
- There is no point in having a receiving end of a channel without senders, we should make a
Spawnerto push async tasks to the executor - In the snippet above, we still need to implement the .waker() method for tasks
We’ll tackle both of these problems in the following sections.
Implementing a Spawner
The spawner provides a way to send tasks to the executor. In practical terms that means that a Spawner is a wrapper around a SyncSender:
#[derive(Clone)]
pub struct Spawner {
task_sender: std::sync::mpsc::SyncSender<Arc<Task>>,
}
Because both ends of a channel are created simultaneously with the mpsc::sync_channel function, our executor and spawner are also constructed by the same function:
pub fn new_executor_spawner() -> (Executor, Spawner) {
const MAX_QUEUED_TASKS: usize = 10_000;
let (task_sender, ready_queue) = mpsc::sync_channel(MAX_QUEUED_TASKS);
(Executor { ready_queue }, Spawner { task_sender })
}
Now is also a good point to consider where the Spawner and Executor will live in a program. In most cases the executor will live for the duration of the program, so it could be useful to store it in static memory. Alternatively, the executor could be created in the main function and live there for the rest of the program. The Spawner can be cloned and sent to as many threads as needed, so it can be included in every Task for easy spawning.
Storing the Spawner in static memory could also work and keeps Tasks small. However, for this example it is more trouble than it's worth.
For simplicity’s sake, we’ll create the executor in the main function, and include spawners within every task. That way we don’t have to deal with static state, synchronization, or graceful shutdown problems. For now, just add a spawner field to Task:
pub(crate) struct Task {
future: Mutex<Pin<Box<dyn Future<Output = ()> + Send + 'static>>>,
spawner: Spawner,
}
To finish the Spawner, it needs a method to send tasks to the executor. We’ll add two: one to spawn a generic future, and a crate-private method that spawns futures already wrapped in Arc<Task>:
impl Spawner {
pub fn spawn(&self, future: impl Future<Output = ()> + Send + 'static) {
let task = Arc::new(Task {
future: Mutex::new(Box::pin(future)),
spawner: self.clone(),
});
self.spawn_task(task)
}
pub(crate) fn spawn_task(&self, task: Arc<Task>) {
self.task_sender.send(task).unwrap();
}
}
Constructing a Waker
When polling a Future, we need to provide a Context, which in current rust is just a wrapper around a Waker.
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
You can think of a waker as a callback to enqueue the future: when executed, it will make sure that the corresponding task is added to the executor's queue.
This ability is useful when a Future is not finished, but can make no further progress without blocking (e.g. on a read or write operation). In such cases we want the executor to continue with another task, but when the blocking operation becomes unblocked, the executor should return to this unfinished future.
A valid solution is to just keep polling futures in a loop until one of them can make some progress, but that is rather inefficient. The proper solution is to wait for the operating system to signal our program when a previously blocking operation can now make progress.
We’ll get back to calling the wake() method when we implement the reactor. First, let’s look at how we can create a Waker object for our executor to pass to the poll function in the first place. A Waker is a simple wrapper around a RawWaker, and a RawWaker contains the type-erased data of the task to be awoken, as well as a virtual method table (abbreviated as "vtable") of the methods that can be applied to that data.
// std::task::RawWaker
impl RawWaker {
pub const fn new(data: *const (), vtable: &'static RawWakerVTable) -> RawWaker
}
impl RawWakerVTable {
pub const fn new(
clone: unsafe fn(_: *const ()) -> RawWaker,
wake: unsafe fn(_: *const ()),
wake_by_ref: unsafe fn(_: *const ()),
drop: unsafe fn(_: *const ())
) -> RawWakerVTable
}
In our case, the data argument to RawWaker::new will be a pointer value that is really an Arc<Task>. That means we need to be careful with properly incrementing the reference count of that arc.
The RawWakerVTable stores 4 functions that operate on the data (our Arc<Task> represented as a type-erased pointer). Then, the clone function should just defer to the clone function of the Arc<Task>, incrementing its refcount. The drop function works analogously.
fn clone(ptr: *const ()) -> RawWaker {
let original: Arc<Task> = unsafe { Arc::from_raw(ptr as _) };
// Increment the inner counter of the arc.
let cloned = original.clone();
// now forget the Arc<Task> so the refcount isn't decremented
std::mem::forget(original);
std::mem::forget(cloned);
RawWaker::new(ptr, &Task::WAKER_VTABLE)
}
fn drop(ptr: *const ()) {
let _: Arc<Task> = unsafe { Arc::from_raw(ptr as _) };
}
The interesting bit is the wake method, and its sibling wake_by_ref (which can sometimes be implemented more efficiently). Especially in the wake_by_ref case we have to be very careful so that the reference count remains correct.
fn wake(ptr: *const ()) {
let arc: Arc<Task> = unsafe { Arc::from_raw(ptr as _) };
let spawner = arc.spawner.clone();
spawner.spawn_task(arc);
}
fn wake_by_ref(ptr: *const ()) {
let arc: Arc<Task> = unsafe { Arc::from_raw(ptr as _) };
arc.spawner.spawn_task(arc.clone());
// we don't actually have ownership of this arc value
// therefore we must not drop `arc`
std::mem::forget(arc)
}
It is then convenient to create the vtable in a const. Finally we can create a waker from an Arc<Task>:
impl Task {
const WAKER_VTABLE: RawWakerVTable =
RawWakerVTable::new(clone, wake, wake_by_ref, drop);
pub fn waker(self: Arc<Self>) -> Waker {
let opaque_ptr = Arc::into_raw(self) as *const ();
let vtable = &Self::WAKER_VTABLE;
unsafe { Waker::from_raw(RawWaker::new(opaque_ptr, vtable)) }
}
}
Why is all this unsafe pointer business required here? It looks like the code could use a Wake trait instead:
pub trait Wake {
// You could also remove this method and set Clone as supertrait instead
fn clone(&self) -> Self;
fn wake(self);
fn wake_by_ref(&self);
// Kind of redundant due to the Drop trait
fn drop(&mut self);
}
impl Wake for Arc<Task> {
fn clone(&self) -> Self {
self.clone()
}
fn wake(self) {
self.spawner
.task_sender
.send(self.clone())
.unwrap;
}
fn wake_by_ref(&self) {
self.spawner
.task_sender
.send(self.clone())
.unwrap;
}
fn drop(self) {
// Decrementing the reference count is done automatically when the
// Arc goes out of scope, so no work is required here
}
}
pub struct Waker {
raw: &'static dyn Wake,
}
This hypothetical Waker implementation uses dynamic dispatch (dyn Wake) instead of static dispatch (impl Wake) because a generic type parameter would only further complicate the signature of Future::poll. Even so this implementation has a major issue: it doesn't work!
Attempting to compile this code results in an error about how the Wake trait cannot be turned into an object, due to the fact that .clone() returns Self. It also gives the following hint:
note: for a trait to be "object safe" it needs to allow building a vtable to allow the call to be resolvable dynamically
And that concludes the reason why wakers require a manual vtable. The requirement of erased types combined with a Clone bound make it impossible to use a more standard trait-based approach.
Fun fact: the futures crate provides the ArcWake trait, which only requires an implementation of wake_by_ref for the implementing type wrapped in an Arc. It then provides functions to convert any ArcWake structure into a fully functional Waker. We basically did the same thing manually here, hopefully making it clear what happens behind the scenes.
Implementing the Reactor
Remember that a Waker is basically a callback trigger, and that it’s up to us to move it somewhere where it will be called again, preferably as soon as we have reason to believe that the corresponding future can complete. That somewhere is often (but not always!) a reactor.
When futures that depend on certain OS events are created, they can register this interest in the reactor. Then, if the future fails to complete in one go, they pass their waker to the reactor. The reactor’s job is to wait until the OS informs them that the awaited event happened, and then wake the associated waker so that the future may be polled again.
Implementing this event subscription functionality for every OS separately is a huge pain. Fortunately, the mio crate provides a generic interface that works on many operating systems, so we’ll use that to make our lives easier.
The Reactor has two components:
- a
mio::Registrythat handles interaction with the OS - a collection of
Wakers, the callbacks that re-enqueue a future when we have reason to believe it can make progress
The mio::Registry type handles the bookkeeping of what events from the OS we are interested in. The type features the register method, which takes three parameters: a source, a Token, and the types of events we’re interested in. The source can be, for instance, a TcpStream, TcpListener, or UdpSocket – things with events managed by the OS. The Token allows us to identify the source that triggered a notification. The types of events we can choose from are for instance a source becoming readable, writable, or both.
For storing the wakers, we need to be a bit careful that OS events are never missed. If a readiness event occurs but we don't wake the future, the future will never make progress again.
More mature implementations typically handle this issue by registring the waker regardless of whether it will be needed. In our case we'll store not just a mapping from Tokens to Wakers, but also make it possible to store that an event of interest happened. That value can be used to just immediately wake the corresponding future later.
pub enum Status {
Awaited(Waker),
Happened,
}
Now we can define our Reactor, containing the Registry of OS interests, and a HashMap of event statuses (wrapped in another Mutex to be able to mutate it through a shared reference):
pub struct Reactor {
registry: Registry,
statuses: Mutex<HashMap<Token, Status>>,
}
Because futures need access to the Reactor, and the reactor generally lives for the duration of the program, it is convenient to store it in static memory.
impl Reactor {
pub fn get() -> &'static Self {
static REACTOR: OnceLock<Reactor> = OnceLock::new();
REACTOR.get_or_init(|| {
let poll = mio::Poll::new().unwrap();
let reactor = Reactor {
registry: poll.registry().try_clone().unwrap(),
statuses: Mutex::new(HashMap::new()),
};
std::thread::Builder::new()
.name("reactor".to_owned())
.spawn(|| run(poll))
.unwrap();
reactor
})
}
}
This function returns a static reference to the reactor, quickly creating one if it didn’t exist yet. Note that, when we finish initializing the Reactor, we also spawn a thread to execute `run(poll)``. That thread is responsible for awakening futures after their IO events have occurred. Its implementation is as follows:
fn run(mut poll: mio::Poll) -> ! {
let reactor = Reactor::get();
let mut events = mio::Events::with_capacity(1024);
loop {
poll.poll(&mut events, None).unwrap();
for event in &events {
let mut guard = reactor.statuses.lock().unwrap();
let previous = guard.insert(event.token(), Status::Happened);
if let Some(Status::Awaited(waker)) = previous {
waker.wake();
}
}
}
}
In a nutshell, we use mio’s poll method to retrieve the events sent by our operating system. This is a blocking function that only returns when there are actual events to react to. We then look at the Token associated to that event, and indicate that it has Happened in our HashMap. If a future had already put their waker there, we wake it here so that it may be polled again. When that happens, the future will see the event Happened, and can proceed to do whatever it wanted to do immediately, such as reading data from a socket.
An async UdpSocket
Now let us create a future that registers itself to the reactor. The simplest one to start with is probably an async UdpSocket. It should keep track of a Token so that we can trace back events that it triggered. Additionally, it needs to have a source recognized by mio, in this case mio::net::UdpSocket. This type of non-async socket is a thin wrapper around the UdpSocket included in std, with some additional bookkeeping to make the event listening work properly. Our async UdpSocket looks like this:
pub struct UdpSocket {
socket: mio::net::UdpSocket,
token: Token,
}
To construct one, we’ll use the same signature a the socket from std:
impl Reactor {
fn unique_token(&self) -> Token {
use std::sync::atomic::{AtomicUsize, Ordering};
static CURRENT_TOKEN: AtomicUsize = AtomicUsize::new(0);
Token(CURRENT_TOKEN.fetch_add(1, Ordering::Relaxed))
}
}
impl UdpSocket {
pub fn bind(addr: impl ToSocketAddrs) -> std::io::Result<Self> {
let std_socket = std::net::UdpSocket::bind(addr)?;
std_socket.set_nonblocking(true)?;
let mut socket = mio::net::UdpSocket::from_std(std_socket);
let reactor = Reactor::get();
let token = reactor.unique_token();
Reactor::get().registry.register(
&mut socket,
token,
Interest::READABLE | Interest::WRITABLE,
)?;
Ok(self::UdpSocket { socket, token })
}
}
Notice the socket.set_nonblocking(true) call, it is very important! By default, methods from std’s socket types block when the underlying socket is not readable or writable (depending on the operation). That is not what we want for an async implementation! If the socket were to block on the IO operation, we want to return Poll::Pending immediately so that another future can make progress in the meantime. The UdpSocket::set_nonblocking method configures that socket methods immediately return an error with ErrorKind::WouldBlock. This allows us to handle that case appropriately, which we’ll do right now by adding a send_to method:
impl UdpSocket {
pub async fn send_to(&self, buf: &[u8], dest: SocketAddr)
-> std::io::Result<usize>
{
loop {
match self.socket.send_to(buf, dest) {
Ok(value) => return Ok(value),
Err(error) if error.kind() == ErrorKind::WouldBlock => {
std::future::poll_fn(|cx|
Reactor::get().poll(self.token, cx)
).await?
}
Err(error) => return Err(error),
}
}
}
}
For the most part, this method is pretty straightforward: if sending with the underlying socket succeeds, it succeeds, and if sending fails with some fatal error, it fails. The less obvious part is when sending fails because the socket was not writable, and returned an error with ErrorKind::WouldBlock. In that case, we want to wait asynchronously until the reactor indicates that we can probably make progress, and then try again.
We use the poll_fn function, which provides a Context parameter and expects a Poll return value: the same signature as the Future::poll method. poll_fn is useful for creating simple Future implementations in-line. Alternatively, you could create a struct containing the Token, implement Future for it, and await that instead. Either way, we call a poll method from the Reactor, which we still need to define. Doing so completes the core functionality of our runtime, so give yourself a pat on the back for making it this far!
impl Reactor {
pub fn poll(&self, token: Token, cx: &mut Context) -> Poll<io::Result<()>> {
let mut guard = self.statuses.lock().unwrap();
match guard.entry(token) {
Entry::Vacant(vacant) => {
vacant.insert(Status::Awaited(cx.waker().clone()));
Poll::Pending
}
Entry::Occupied(mut occupied) => {
match occupied.get() {
Status::Awaited(waker) => {
// skip clone is wakers are the same
if !waker.will_wake(cx.waker()) {
occupied.insert(Status::Awaited(cx.waker().clone()));
}
Poll::Pending
}
Status::Happened => {
occupied.remove();
Poll::Ready(Ok(()))
}
}
}
}
}
}
If there was no status inserted previously, we simply store the waker, so that the run function will respawn the future when the event happens. If there was already a waker there, we update it if it’s different from the waker in our current context, which the idiomatic approach to handling this case. We never call this function twice for the same Token without being awakened first, so in our case this branch will never match (and even if it did, the waker would always be equal as it consists of a pointer to the same Task and uses the same vtable). Finally, if the event has Happened, we indicate that the future can continue immediately. This will cause the send method to try sending again, with a reasonable chance that it will succeed this time.
Note that, because we registered with both READABLE and WRITABLE interests, the reactor might wake a future that wants to perform a send because the socket has become readable, which is not enough to be able to send data. For this reason, many runtimes actually split these events.
The socket is registered with mio upon creation, and should be deregistered when the UdpSocket is dropped:
impl Drop for UdpSocket {
fn drop(&mut self) {
let _ = Reactor::get().registry.deregister(&mut self.socket);
}
}
To complete our UdpSocket, we can apply the exact same strategy to the recv method:
pub async fn recv_from(&self, buf: &mut [u8]) -> std::io::Result<(usize, SocketAddr)> {
loop {
match self.socket.recv_from(buf) {
Ok(value) => return Ok(value),
Err(error) if error.kind() == ErrorKind::WouldBlock => {
std::future::poll_fn(|cx| Reactor::get().poll(self.token, cx)).await?
}
Err(error) => return Err(error),
}
}
}
Putting it all to use
There is only one thing left to do, and that is to actually use our new runtime! Remember that we have to initialize the executor in the main function of our program. We can then spawn our first async task, which can spawn other tasks, and those tasks can spawn even more tasks, and all of them are run by our executor:
fn main() {
let (executor, spawner) = new_executor_spawner();
spawner.spawn(async_main());
// Drop this spawner, so that the `run` method can stop as
// soon as all other spawners (stored within tasks) are dropped
drop(spawner);
executor.run();
}
async fn async_main() {
let socket = executor::UdpSocket::bind("127.0.0.1:8000").unwrap();
// Receives a single datagram message on the socket.
// If `buf` is too small to hold the message, it will be cut off.
let mut buf = [0; 10];
let (amt, src) = socket.recv_from(&mut buf).await.unwrap();
// Redeclare `buf` as slice of the received data
// and send reverse data back to origin.
let buf = &mut buf[..amt];
buf.reverse();
socket.send_to(buf, src).await.unwrap();
}
On unix systems we can use netcat to send some data to the socket:
> echo "bar" | nc 127.0.0.1 8000 -u
rab
Summary
Let’s go over everything an async runtime does one more time:
We started by writing the Executor, which continuously polls tasks that come through its receiving end of a channel.
Then, we created a Spawner, which allows pushing tasks into the channel, When the executor polls a task, it constructs a Waker that – through a somewhat complicated interface – allows spawning the associated task again.
When a future is polled and cannot complete immediately, it hands that waker to the Reactor. The reactor continuously waits for events that are being awaited by tasks, and uses their waker to spawn them when those events happen.
When awakened, the waker’s spawner pushes the task back into the queue of the executor, which will then poll them again, and the cycle repeats until all tasks are done.
And that’s it! A functional async runtime with mio. Hopefully, you now have all the knowledge required to work on your Future. If you’re looking for some fun exercises, you can extend this runtime with operators like join! and select!, implement async timers, or experiment with making an async mutex.
Code
The full code can be found here. If you have any questions, tips, or suggestions, feel free to contact us!
Funding
This example is part of our work on nea, a webserver that never allocates. This work has been funded by the NLnet Foundation.
Care to sponsor open-source software?
We would like to do further R&D on zero-allocation webservers. Please contact us if you're interested in funding this work!