What is my fuzzer doing?
Fuzz testing is incredibly useful: it has caught many a bug during the development of NTP packet parsing and gzip/bzip2 (de)compression.
But I've always been unsatisfied with the fuzzer being a black box. When it runs for hours and reports no issues, what do we actually learn from that? In ntpd-rs we've previously had a bug fly under the radar because the fuzzer just did not reach a large chunk of code. So, does my fuzzer actually exercise the code paths that I think it should?
Code coverage
We have good tooling for determining whether our test suite exercises certain parts of our code base. The cargo llvm-cov command makes this a simple as:
cargo llvm-cov test --open
That command will open up a table displaying various kinds of coverage for your codebase based on what code paths your tests exercise.
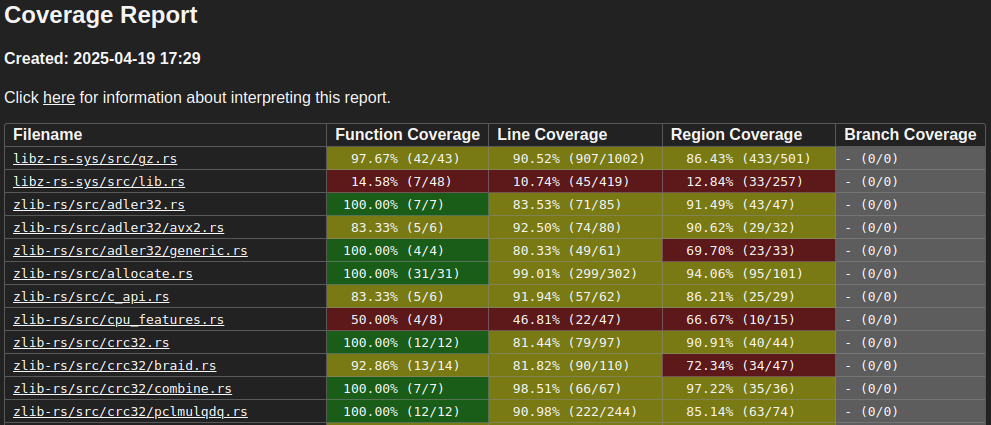 Image: Output html table of cargo llvm-cov
Image: Output html table of cargo llvm-cov
However, support for cargo test is hardcoded into cargo llvm-cov. It does not currently support getting coverage information out of a fuzzer.
Fuzzer coverage
The cargo fuzz command appears to have a solution:
> cargo fuzz --help
A `cargo` subcommand for fuzzing with `libFuzzer`! Easy to use!
Usage: cargo-fuzz <COMMAND>
Commands:
...
run Run a fuzz target
coverage Run program on the generated corpus and generate coverage information
We can run this for our favorite fuzz target, here uncompress from zlib-rs:
> cargo +nightly fuzz coverage --features=disable-checksum uncompress
Generating coverage data for corpus "~/rust/zlib-rs/fuzz/corpus/uncompress"
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 291926156
INFO: Loaded 1 modules (27951 inline 8-bit counters): 27951 [0x5b488a874440, 0x5b488a87b16f),
INFO: Loaded 1 PC tables (27951 PCs): 27951 [0x5b488a87b170,0x5b488a8e8460),
MERGE-OUTER: 5317 files, 0 in the initial corpus, 0 processed earlier
MERGE-OUTER: attempt 1
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 331385751
INFO: Loaded 1 modules (27951 inline 8-bit counters): 27951 [0x5b1971f7f440, 0x5b1971f8616f),
INFO: Loaded 1 PC tables (27951 PCs): 27951 [0x5b1971f86170,0x5b1971ff3460),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 1048576 bytes
MERGE-INNER: using the control file '/tmp/libFuzzerTemp.Merge135507.txt'
MERGE-INNER: 5317 total files; 0 processed earlier; will process 5317 files now
#1 pulse cov: 141 ft: 142 exec/s: 0 rss: 36Mb
#2 pulse cov: 142 ft: 143 exec/s: 0 rss: 36Mb
#4 pulse cov: 159 ft: 160 exec/s: 0 rss: 36Mb
#8 pulse cov: 214 ft: 220 exec/s: 0 rss: 36Mb
#16 pulse cov: 287 ft: 300 exec/s: 0 rss: 36Mb
#32 pulse cov: 340 ft: 401 exec/s: 0 rss: 37Mb
#64 pulse cov: 466 ft: 664 exec/s: 0 rss: 39Mb
#128 pulse cov: 542 ft: 934 exec/s: 0 rss: 42Mb
#256 pulse cov: 578 ft: 1151 exec/s: 0 rss: 48Mb
#512 pulse cov: 588 ft: 1333 exec/s: 0 rss: 59Mb
#1024 pulse cov: 592 ft: 1480 exec/s: 0 rss: 78Mb
#2048 pulse cov: 646 ft: 1716 exec/s: 0 rss: 114Mb
#4096 pulse cov: 766 ft: 2569 exec/s: 0 rss: 191Mb
#5317 DONE cov: 798 ft: 3319 exec/s: 0 rss: 266Mb
MERGE-OUTER: successful in 1 attempt(s)
MERGE-OUTER: the control file has 703068 bytes
MERGE-OUTER: consumed 0Mb (43Mb rss) to parse the control file
MERGE-OUTER: 500 new files with 3319 new features added; 798 new coverage edges
Merging raw coverage data...
Coverage data merged and saved in "~/rust/zlib-rs/fuzz/coverage/uncompress/coverage.profdata".
This compiles the fuzzer so that it tracks coverage, and then runs your fuzz target over all of the files in the corpus for this fuzzer. The combined coverage data is then stored in coverage.profdata.
Before we look at that output, let's think about what coverage we'd expect a fuzzer to have, and what factors influence how good the coverage is.
A good corpus
Intuitively, a fuzzer generates a random input, runs your program with that input, and reports any errors (usually failed assertions, but also memory leaks or other correctness problems).
Unfortunately, for most programs, random input data never exercises the interesting parts of your business logic. Such inputs are quickly rejected because of their structure, or because they fail an integrity check (magic bytes, checksum, etc.).
One way to guide the fuzzer to generate more interesting inputs is to use the Arbitrary trait to create a meaningful value of a type. We use this approach for configuration structs, where we want to test that all combinations of inputs work without issues.
However for our uncompress fuzzer, it should be able to handle an arbitrary stream of bytes, but we'd like to guide it to correct, or almost-correct streams of bytes so that more esoteric error conditions are hit. The tool for that job is a custom corpus.
The corpus is the initial collection of input data for the fuzzer. By default the fuzzer starts from random bytes, but the corpus can be seeded with dedicated input. For this fuzzer, I made the compression-corpus. This program constructs gzip and bzip2 files that cover the full matrix of the available settings, so they should exercise much of the decompression logic.
 Image: The bzip2 and gzip files generated by the compression corpus
Image: The bzip2 and gzip files generated by the compression corpus
The fuzzer will then slowly modify these inputs, making it quite likely that the input is not immediately rejected, but instead fails somewhere deep in the business logic. Fuzzing with such input makes it much more likely that interesting code paths are taken. In combination with running the fuzzer for a long enough time, it should be able to hit all of the reachable logic.
But how do we determine that our handcrafted corpus is any good? Let's now look a our coverage report!
Generating a coverage report
The llvm-cov command can be used to turn our coverage.profdata into something more readable. This took a lot of fiddling around, but here is the command for that:
$(rustc --print sysroot)/lib/rustlib/$(rustc --print host-tuple)/bin/llvm-cov show \
target/$(rustc --print host-tuple)/coverage/$(rustc --print host-tuple)/release/uncompress \
-instr-profile=fuzz/coverage/uncompress/coverage.profdata \
-Xdemangler=rustfilt \
--format=html \
-output-dir=/tmp/coverage \
-ignore-filename-regex="\.cargo|\.rustup|fuzz_target"
This command calls llvm-cov (note, this is not the same thing as cargo llvm-cov!) with the fuzz binary and the coverage.profdata that we've gathered, to generate the same neat html table that cargo llvm-cov did for our tests. Some notes:
- The
llvm-covbinary can be installed withrustup component add llvm-tools-preview - The
rustfiltbinary is used to demangle rust symbolscargo install rustfilt - The
rustc --printcommands are to make this script more portable between architectures and rust/LLVM versions - Without
-output-dir, a single html file is emitted to stdout. I found that file hard to interpret, the html table is much nicer - We ignore coverage for dependencies, the standard library, and the fuzzer itself
It's a lot more tedious than cargo llvm-cov test, but we got our coverage report.
Error branches
Looking through the coverage report, overall it touched the code that I thought it should, and didn't touch parts that it clearly shouldn't.
But I could see that basically all error handling code was uncovered; for instance, the then-branch of this if:
if hold as u16 != !((hold >> 16) as u16) {
mode = Mode::Bad;
break 'label self.bad("invalid stored block lengths\0");
}
That is strange because this error condition should be easily reachable by slightly corrupting a valid gzip file. Also, it wasn't just this error condition, but seemingly all error handling logic. That is extremely unlikely, so something weird must be going on.
After a while, I remembered that the fuzzer I was experimenting with uses a cool feature that I did not know about before @inahga wrote this fuzzer during a security audit of zlib-rs.
Before then, my fuzzers would simply return; on undesired input. That works, but misses an opportunity to tell the fuzzer that that input was uninteresting. The uncompress fuzzer instead returns a value of type libfuzzer_sys::Corpus:
pub enum Corpus {
Keep,
Reject,
}
Using the Corpus type we can tell the fuzzer when to keep an input in its corpus. Inputs that are trivially invalid (incorrect length, missing magic bytes, etc.) are rejected, so hopefully more fuzz time is spent on interesting inputs.
But when determining code coverage, we actually want to also see what error conditions are reached: we want some invalid inputs to remain in the corpus, so that cargo fuzz coverage reports that we cover the error paths.
I have now added a custom feature flag that always Keeps the input. With this change, the coverage info of the error paths is now correctly reported.
CI
We use codecov to visualize the code coverage of our CI runs. Besides the coverage of our unit tests for various platforms, we now also track and can easily look at the coverage of our 2 most important fuzz tests: compress and uncompress. This is the relevant part of the CI action:
- name: Run `cargo fuzz`
run: |
cargo fuzz run ${{matrix.features}} ${{matrix.fuzz_target}} ${{matrix.corpus}} -- -max_total_time=10
- name: Fuzz codecov
run: |
cargo fuzz coverage ${{matrix.features}} ${{matrix.fuzz_target}} ${{matrix.corpus}}
$(rustc --print sysroot)/lib/rustlib/$(rustc --print host-tuple)/bin/llvm-cov export -Xdemangler=rustfilt \
target/$(rustc --print host-tuple)/coverage/$(rustc --print host-tuple)/release/${{matrix.fuzz_target}} \
-instr-profile=fuzz/coverage/${{matrix.fuzz_target}}/coverage.profdata \
--format=lcov \
-ignore-filename-regex="\.cargo|\.rustup|fuzz_targets" > lcov.info
In this case we use our custom initial corpus both for running the fuzzer, and for determining the coverage. The output format is now lcov because that is what codecov wants. The full fuzz-code-coverage action can be found here.
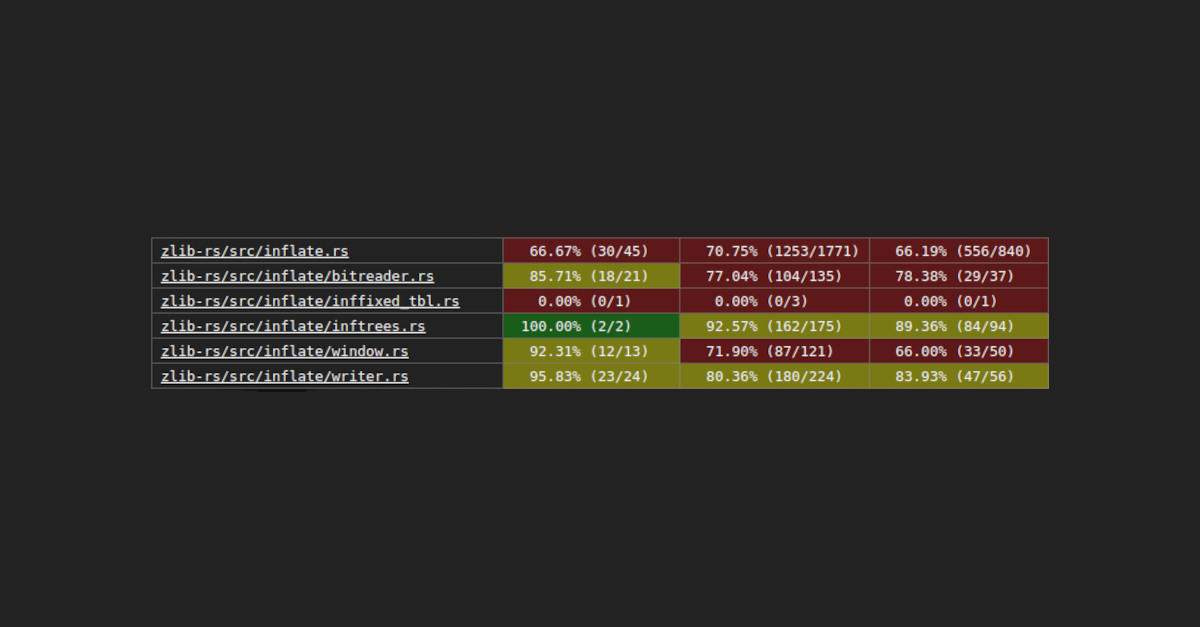
We can then observe what parts of the file are covered, e.g. in inflate.rs. We can also see, especially when making changes to the fuzzer, that we still cover everything we did before, and hopefully more. See here for an example.
We only run the fuzzer for a short time on each CI run (10 seconds in this case), making it all the more crucial to start with a good corpus. Before releases we run the fuzzer for longer to make sure we find any lingering bugs.
Results
With all of that setup, I was finally able to evaluate my custom corpus. These are the results for inflate.rs:
| Corpus | Fuzz Time | Function Coverage | Line Coverage | Region Coverage |
|---|---|---|---|---|
| no custom corpus | 10s | 62.22% | 52.17% | 45.12% |
| compression corpus | 10s | 66.67% | 70.98% | 66.55% |
| compression corpus + error paths | 10s | 66.67% | 74.36% | 69.64% |
The custom compression corpus is extremely effective: after just 10 seconds, we get much better coverage with the custom corpus than with random data. By manually inspecting the coverage report, we do now in fact reach all of the expected logic.
Conclusion
We now get very detailed code coverage of our fuzzers on every CI run, and can easily see their coverage locally by copy-pasting some commands.
Figuring out how to make fuzz coverage work was tough. The llvm-cov tool is not the easiest to use, and the cargo fuzz coverage documentation is out of date. Ultimately, I'd like cargo llvm-cov to do the heavy lifting here, see this PR.
It is fascinating to be able to see what difference a custom corpus makes. I've always been told that the corpus matters, but seeing the results for a codebase that I'm familiar with really drives that point home.
Having the coverage report has already made us tweak our fuzzers, and hopefully it'll help improve yours too!