How we sped up our GitLab pipelines
One of the main aspects of CI/CD is running an automated pipeline every time that new code is pushed to the central repository. This automated pipeline includes tasks such as linting, compiling, bundling, testing and creating release artifacts. Even deploying the application to a staging or production environment can be done automatically.
GitLab CI
For our CI, we use GitLab CI, a tool included in GitLab that allows you to specify your own pipeline by writing a set of jobs. Each of these jobs runs a specific set of commands that completes a part of the automated pipeline. In GitLab these jobs run in stages where all jobs in a stage run in parallel, but all stages run in sequence, one after the other. Each job is run on a separated environment by a process called a runner.
Initially our pipelines weren't too complicated. In general, we defined four different stages:
- Lint: Check the application for code style issues.
- Build: Build, compile and package the application, this generally resulted in a set of docker images.
- Test: Run the tests and check if everything still works.
- Deploy: Deploy the application on a staging environment, and optionally deploy it to production once approved.
The javascript problem
Many of our projects use javascript and/or typescript; both for the frontend web application and often for the backend API server as well. Unfortunately we had one big issue with the javascript ecosystem: dependencies. As any web developer will know: a javascript project quickly gathers hundreds of dependencies and sub-dependencies. Installing those can take a long time, as it often involves unpacking thousands of files to the filesystem. An additional problem here is that GitLab runs each job on a clean environment, so every additional job we specified needed to install all dependencies all over again.
GitLab luckily offers a caching mechanism to allow you to share some files between different runners. One solution would be to cache the node_modules folder. Frustratingly, the way GitLab CI caching works means zipping files to be cached and then uploading the result to a shared cache server. Given the enormous amount of files that the node_modules directory can contain, the caching mechanism of GitLab actually was at the best of times just as quick as simply installing the dependencies.
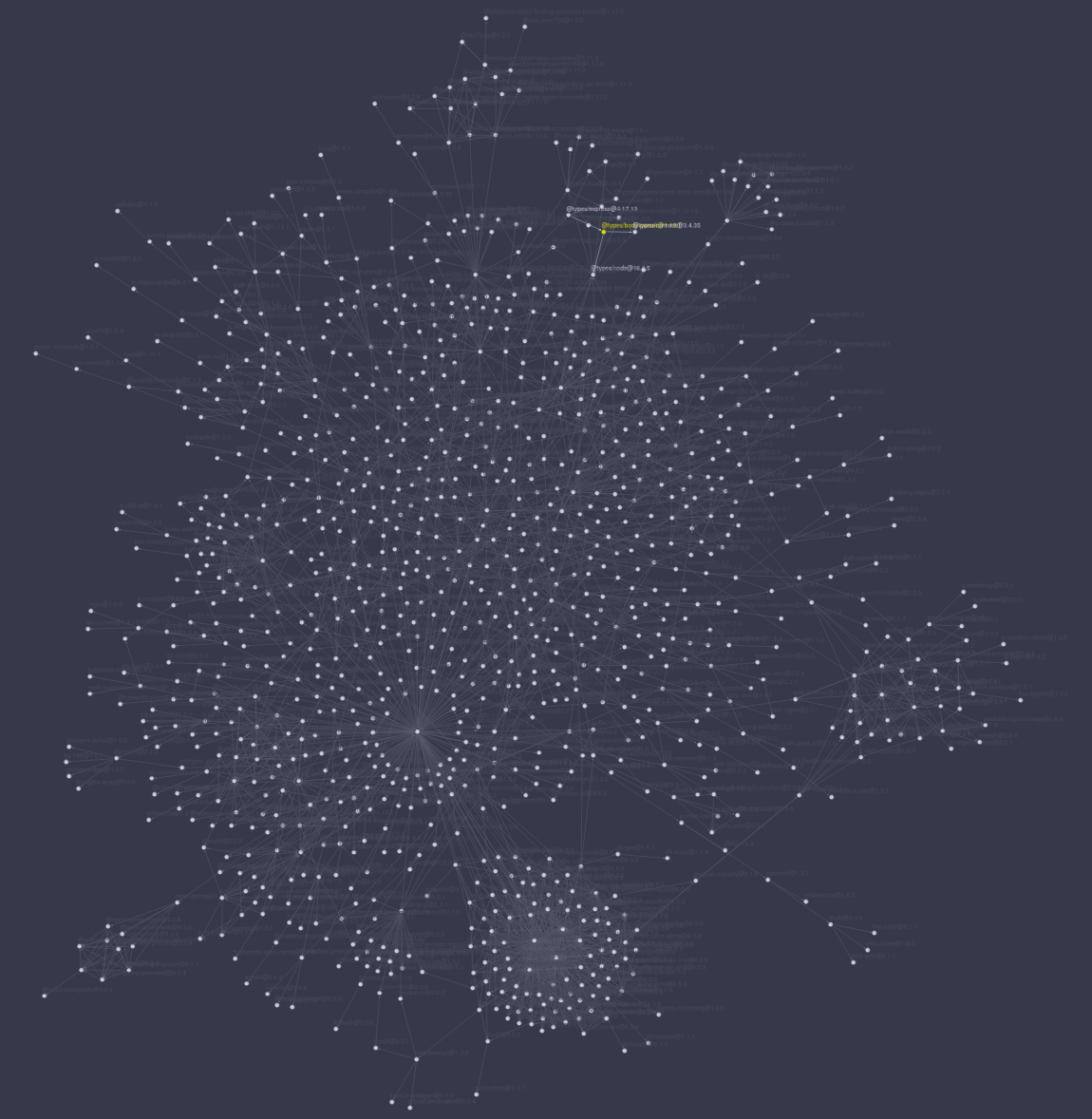
Dependency graph for one of our projects
We went for the easy way out: we combined all our stages and all our jobs in one. One big job that would do it all: lint the code, compile the typescript, bundle the modules and build the docker images that we eventually deploy. Our deploy step was the only separate job remaining. Our pipeline was still downloading and unpacking dependencies every time though, every time taking several minutes just to get the dependencies in the right place.
More troubles
This worked for a while, but we weren't out of the woods just yet. After a while our pipeline started slowing down more and more. The cause? Our ever-growing set of integration tests. Testing a web application generally involves just opening a browser and letting a testing tool click through your application. While such a tool is pretty fast in general, once you start to go through hundreds of scenarios running them all one after the other takes a lot of time.
This was becoming a problem. We were waiting for well over 30 minutes just to get a failed test about some typo. It was quickly becoming Continuous Waiting instead of Continuous Integration.

Yarn to the rescue
Our first attempt involved yarn. Until now we installed our dependencies using Yarn 1. While in general it is a bit faster than NPM it didn't gain us much speed. Yarn 2 (berry) however is a whole different story: it includes PnP mode, where your packages aren't extracted into a node_modules directory. Instead, Yarn 2 just downloads the zip files for each library and keeps them zipped. Then, once a dependency is required, it is directly served from the zip file. This not only saves a bit of disk space, it also hugely reduces the number of files.
Now our GitLab caching mechanism could shine: instead of having to zip thousands of files, only at most several hundred relatively small zip files needed to be cached. Instead of taking minutes to zip and unzip, it only took seconds to zip and upload the cache. And there was another advantage: the cache works across pipelines, so even a fresh pipeline run didn't need to download dependencies: it only took a few seconds to go from starting the pipeline to linting the code.
We went back to our initial pipeline design: not one big job, but several smaller ones running in four different stages: lint, build, test, deploy. It was a much needed cleanup, but it actually made things a tiny bit slower compared to the single job: we needed to download and upload the cache a few times. However, it opened up the biggest speedup of the bunch: parallelization.
Parallel testing
We were still running all our tests sequentially: first run test A, then run test B and so on. But we now had something that we didn't have before: we could start new jobs with very little overhead, as it only took seconds to go from starting a job to actually being ready to run commands.
We split up our tests in several folders, and created several testing jobs instead of a single one: each testing job would run all tests in a single folder, all of them combined would run all the tests. Now they could run in parallel and we were only limited by the number of runners currently available.
Our pipelines were now running well below 15 minutes. They were still somewhat limited by our runner capacity, but in principle we could parallelize as much as we can. Having dozens of jobs that each only take a minute to complete isn't a problem as long as you have the capacity and as long as the overhead of running a separate job isn't too high.
Out of order
There was still one thing to do though, our final improvement that managed to shave of a few more seconds, but more importantly: getting feedback more quickly. GitLab allows jobs to specify their needs. Say for example we have some tests that only test the backend API responses. For those tests we don't need to wait for the build of the frontend to complete.
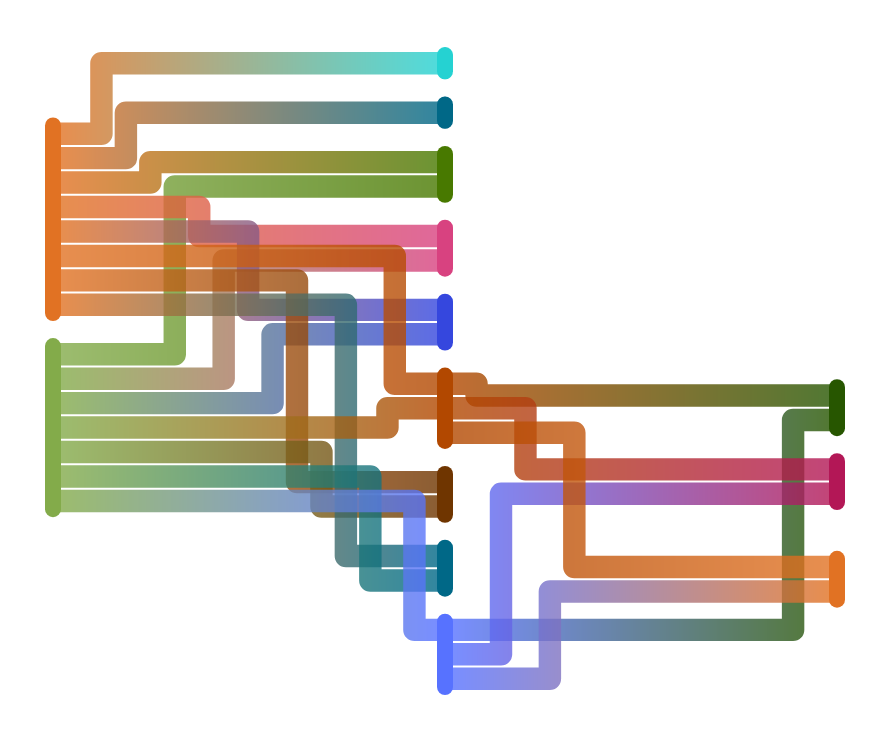
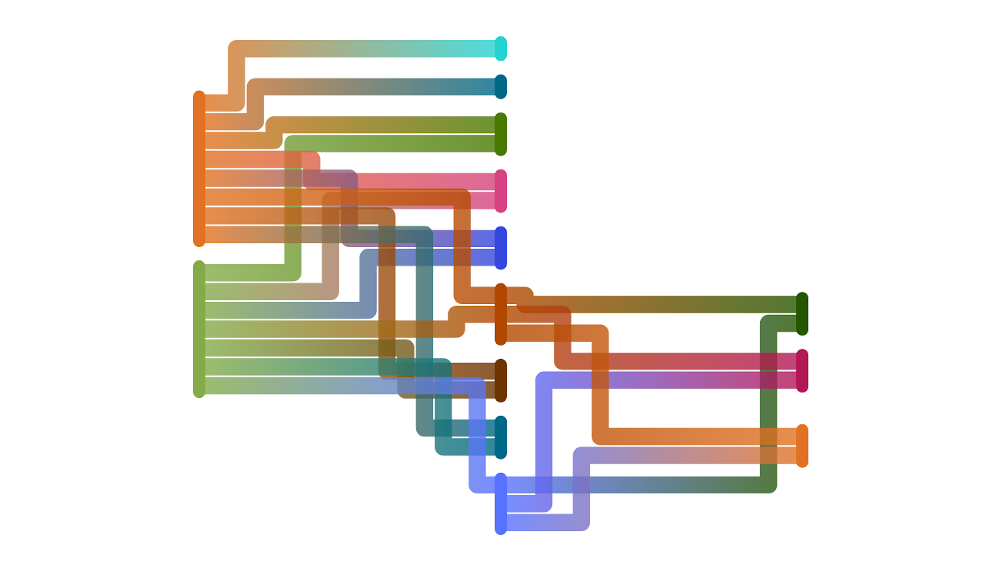
Example of out of order job execution graph generated by GitLab
This means that capacity of our runners is spread more evenly: jobs run as soon as they can be run, and not all jobs will spawn at the same time. Sometimes our backend tests are already finished before the jobs of the frontend tests have even started, meaning we free up more runners for those frontend jobs. It also means that developers get their feedback earlier: the backend tests run as soon as possible and the pipeline will fail as soon as there is an error in those tests. This enabled the developers to go back quickly and fix the tests, sometimes even before they started working on another issue, which prevents them from having to switch contexts between different issues.
Results
All in all, our average pipeline went from a little under 40 minutes down to a little over 14 minutes. It's still not lightning-fast, but we now have a way to speed it up even more and scale up our tests suite while preventing a slowdown in the future.