Power consumption of an experimental webserver

This article was authored by Jordy Aaldering and Folkert de Vries
Over the past couple of months, we teamed up with Bernard van Gastel and Jordy Aaldering at Radboud University's Software Energy Lab to measure nea's energy efficiency.
Nea
Nea is a web server that never allocates. Or perhaps it allocates once, depending on what "allocates" means to you. In any case, nea is designed to never run out of memory, something that many production web servers (written in ruby, python, etc.) apparently do regularly.
In my recent talk at Software you can Love I went into the technical details (slides):
The Experiment
We want to compare nea, and especially nea in combination with roc, versus other languages, to prove that this combination is competitive.
Unfortunately, comparisons across languages and frameworks are hard. Our experiment measures the performance of four small web server implementations. The implementations are not hyper-optimized, but try to all perform the same amount of work.
Our four contenders are
- go: a straightforward implementation in go.
- rust-tokio: a rust implementation that uses
tokioas its async executor. - rust-nea: a rust implementation that uses the nea async executor and platform.
- roc-nea: a roc implementation that uses the nea async executor and platform.
Notably absent are any interpreted languages like ruby or typescript, even though these are still very common in the web space. We were not able to write servers in those languages that we could compare in a fair way: they don't give sufficient control over their runtime, e.g. how many threads are used to handle the workload.
For all of our four implementations, we implemented the same three programs:
csv-svg-path: "parse" (cursed string slicing) a CSV file and produce an SVG.send-static-file: sends a static string and closes the connection. This is mostly a baseline measurement.varying-allocations: allocates and then deallocates large arrays.
The implementations deliberately don't use any external dependencies (beside tokio or nea). The CSV format was chosen because it is so easy to parse with string slicing: using json instead would be unfair because then we'd just be benchmarking the languages' json implementation.
Measurement Setup
The measurement setup consists of an ODROID H3 single-board computer. The ODROID H3 is designed with energy-efficiency in mind and contains an Intel Celeron N5105 CPU with only a 10 Watt TDP. Benchmarks are run on this device through the use of a GitLab pipeline on the Software Energy Lab project. Besides Docker and a GitLab runner, this device has a minimal number of background processes, minimizing the amount of variability in runtime and energy measurements between benchmarks. This measurement setup provides us with exceptional reproducibility of the results.
We have two ways of measuring the energy consumption of this device. Firstly, most modern Intel and AMD processor provide a Running Average Power Limit (RAPL) interface for reporting the accumulated energy consumption of the CPU. We can then determine how much energy was consumed during a benchmark by reading out the difference in the accumulated energy consumption right before and after that benchmark run. Secondly, the ODROID H3 has been equipped with an INA 226 chip. Whereas RAPL allows us to measure the energy consumption of the CPU, the INA chip allows us to measure the energy consumption of the system as a whole (using a similar method).
We benchmark the energy consumption of our benchmarks with the energy-bench crate. This crate contains the functionality for measuring the RAPL and INA energy consumption of code blocks. Before the first benchmark run, the tool determines the idle power consumption, which is the power consumption of the operating system, background tasks, and the baseline power required to keep the hardware itself operational. By excluding idle energy consumption from the results we aim to isolate the program's energy consumption from that of other sources.
Energy Measurements
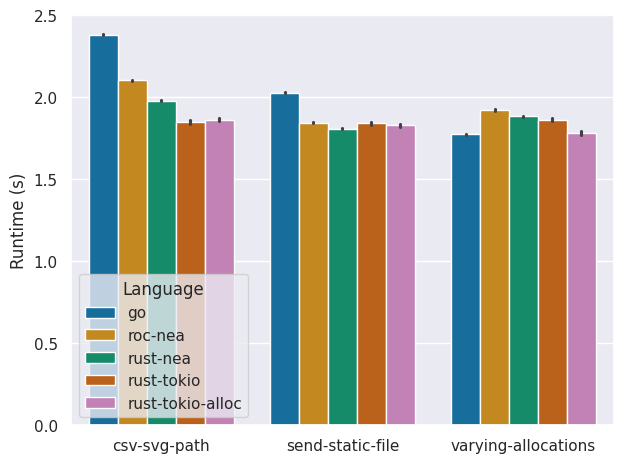
We use the siege http load testing and benchmarking utility to simulate network traffic. The number of concurrent users is set to four, as that is the amount of threads that are available on the ODROID H3. The number of repetitions is set to 5000 to ensure that a single benchmark run takes long enough to gain accurate energy measuring results from the INA chip, which only updates around 8 times per second. Results are averaged over 100 benchmark runs, with black bars representing the standard deviation.
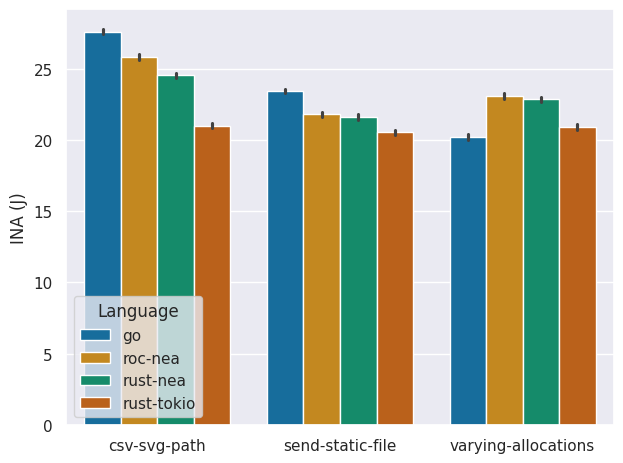
First we determine at a glance whether there is any significant difference in the energy consumption pattern provided by the RAPL and INA energy measurements. Doing so we find that both measuring methods provide a similar energy consumption pattern, albeit with the INA chip reporting about 3 times higher energy consumption, because it measures the system as a whole.
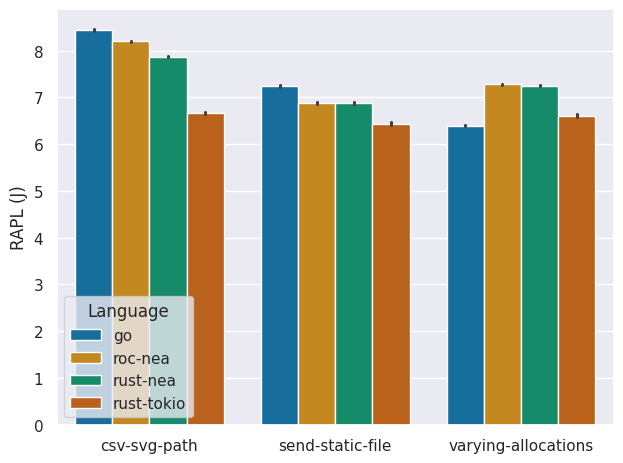
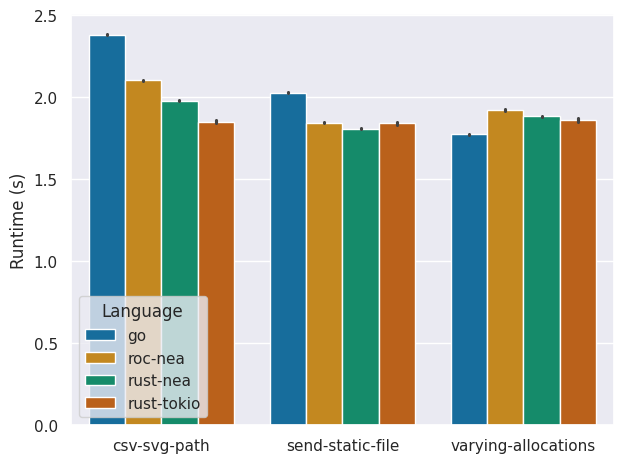
Comparing the energy consumption and runtime we find that, typically, rust-tokio provides the best performance in terms of both runtime and energy-efficiency. Interestingly, for the send-static-file and varying-allocations benchmarks, rust-tokio perform significantly better in terms of energy consumption compared to the two nea variants, even though it has a similar runtime. To ensure memory safety, nea requires additional memory management for each incoming request. And although it seems that this does not necessarily have a negative impact on the runtime performance, it does introduce some energy overhead.
Furthermore, we find that Go performs surprisingly well in the varying-allocations benchmark. This could be due to Go's memory allocator, which initially reserves a block of memory called an arena. Consequently, the varying allocations are faster in Go.
Although Go has a better runtime than rust-tokio in this benchmark, its energy consumption is similar. This discrepancy between runtime and energy-efficiency is potentially a result of garbage collection. The energy consumption introduced by garbage collection seems to offset the gains in energy-efficiency by initially reserving a large block of memory.
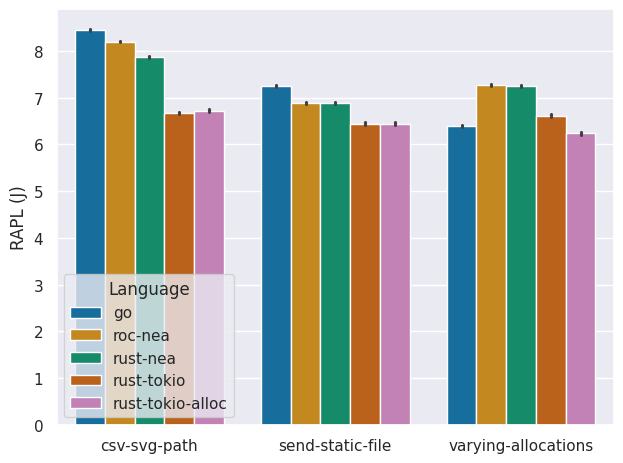
To validate that the increase in runtime performance of Go is due to its allocator, we tested a different allocator for rust-tokio (rust-tokio-alloc). Doing so we see that the runtime performance of the varying-allocations benchmark of rust-tokio-alloc is now indeed similar. Furthermore the energy consumption is now also lower, indicating that indeed the garbage collection introduces some energy consumption overhead.
To determine the competitiveness of Nea's energy consumption in practise, we compare the energy consumption metrics of the INA chip, because these numbers give the whole picture and not just the energy consumption of the CPU. In the worst case for rust-nea, which is the csv-svg-path benchmark, rust-nea consumes 17% more energy than rust-tokio for the 5000 requests. However on average for the three benchmarks it only consumes 11% more energy.
Although Go consumes 13% less energy in the varying-allocations benchmark, on average it still consumes 3% more energy than rust-nea over all three benchmarks. We observe that roc-nea introduces minimal overhead over rust-nea, at only a 2% increase in energy consumption.
Conclusion
We see that nea holds its own: while it is not always the fastest, it performs very well for an experimental project. Further gains are most likely in handling IO and improving the architecture, not in how memory is managed. We also see that Roc as a language adds very little overhead versus rust: this is extremely impressive for a high-level language.