
We often get the question how productive working with Rust is. "We know that it is awesome, but isn't it hard to learn? Don’t you struggle with the borrow checker?". Well, we put it to the test in Google's Hash Code 2019 programming competition.
We often get the question how productive working with Rust is. "We know that it is awesome, but isn't it hard to learn? Don’t you struggle with the borrow checker?". Well, we put it to the test in Google's Hash Code 2019 programming competition.
What better way to rate Rust's productiveness than to expose it to a time-pressure contest against seasoned teams using full-grown languages and ecosystems?
About the contest
Hash Code is a team programming competition where all teams must solve a single engineering problem within a 4-hour time window. This year, over 6000 teams from all over the world competed. We entered a team comprised of two of our developers. And of course, we chose to write our solution in Rust.
The problems presented at Hash Code have always been NP-hard optimization problems, for which approximation solutions need to be implemented. Because each team only gets 4 hours to implement, but also run their solutions, they cannot be CPU intensive. The teams are ranked by scoring the results generated by their approximation solutions.
The problem
This year, the problem involved creating a slideshow from a set of photos. These slideshows are scored on how interesting they are. Each photo has a set of tags associated with them. Two subsequent slides are only as interesting as the number of tags that are represented on both slides, as well as the number of tags that are only on the one and not on the other slide. To make it more interesting, a slide is either comprised of a horizontal (or landscape) photo, or two vertical (or portrait) photos.
The competitors
The competitors we faced (language-wise) were the usual suspects for an engineering problem, notably Java, C/C++, Python, and C#. All worthy opponents, with a big ecosystem and developers who can be expected to have years of experience in the language. For this type of competition, we would expect the most from languages like C++.
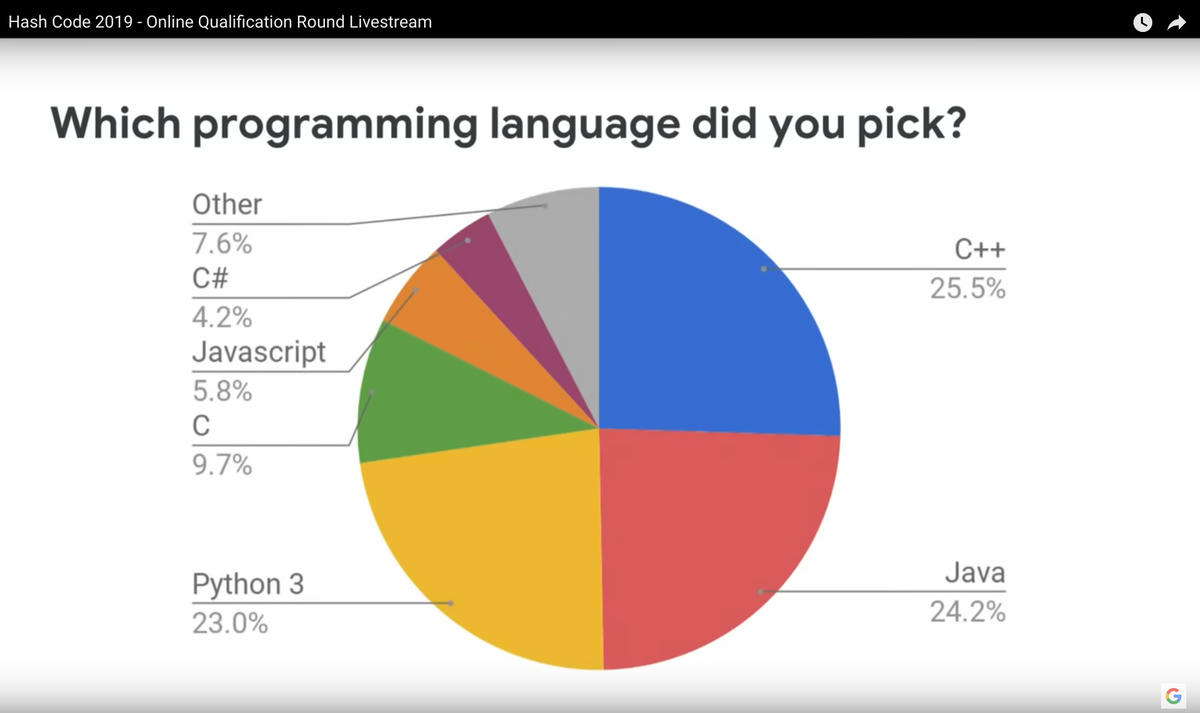 Programming languages used in Hash Code 2019
Programming languages used in Hash Code 2019
Our solution
The slideshow problem is really hard to solve in a smart way, precisely because it is an NP-hard optimization problem. Hence we started off by just making a solution that yields a random valid slideshow. This phase was done after about 10 minutes of reading the exercise and 30 minutes of pair programming. At this stage, the code was pretty nice as well. Pair programming gave us more confidence that we weren't making any stupid mistakes, as well as ensured that both of us had a grasp of the problem and our data structures. This solution scored 287k (winning score 1250k), which is pretty good considering we just emitted random (valid) garbage.
Next up we split up the team to work standalone on separate angles. My colleague continued with the randomness path, adding optimization here and there. The upside of this approach is that you get better results bit by bit. The downside is that it will probably never yield the best scores. I started to implement a classical approximation solution, namely a variant on A* search that yields better results as it goes on. As it turned out this solution would not compute fast enough through the search space to yield better results than the naive approach.
The result
The naive approach, in the end, yielded our best result of 733k, which landed us in 783rd place out of 6000+ teams, or to frame it a little more glamorously: in the top 12% :)
Considering we were a team of two (maximum four) and we didn't have any kind of serious computing power, just our regular desktops, we were happy with our result. We could have performed way better if we had four bright minds.
Our experience during the contest
Rust prevented us from shooting ourselves in the foot on several occasions. And yes, there were moments where the borrow checker would not be satisfied with our code. However, what most people do not realize is that it is often fine to clone an object: as long as the cloning does not result in extra allocations, or does not occur in the innermost loop. Especially with these kinds of problems the real challenges lie in what you choose to approximate and the complexity of your solution.
Rust ended up being very helpful and we managed to be as productive as we could be in any other language.
Productive? Yes!
Sure, this type of engineering problem is a specific use case, and it is a bit of a stretch to infer productivity from it for general purpose software development.
But still, solving a hard programming problem in a short 4-hour window is definitely a scenario where you would expect a non-productive language to fail in dramatic fashion.
All in all, I think it is safe to say that Rust is productive.