Cloud storage simplification and abstraction for Node.js
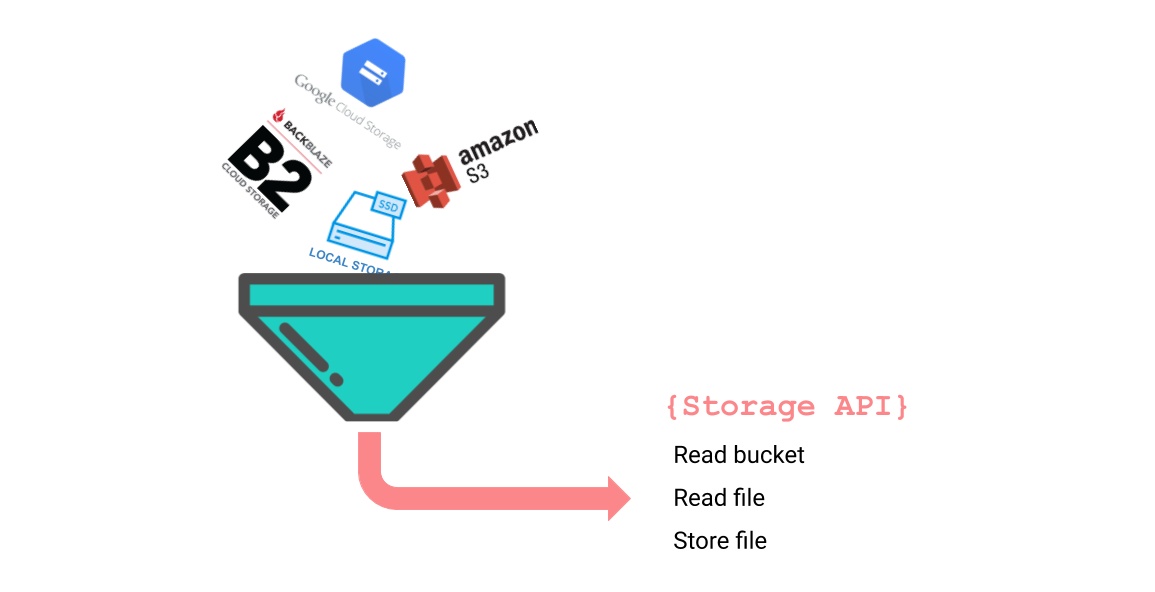
That is why we've decided to write an abstraction layer for the APIs of the most-used storage providers that exposes only a limited set of common storage actions. Keywords are abstraction and simplification, as mentioned in the title.
A little history
The first completely web-based commercial cloud storage was "PersonaLink Service" by AT&T in 1994[1], but the use of cloud storage really took off since Amazon launched S3 in 2006. Today S3 is still one of the most popular cloud storage services.
Because Amazon S3 was the first cloud service that got widely adopted, other cloud services implemented the S3 API in their services to be compliant with S3 and make it easier for customers to hop over to their services. As a consequence, the S3 API has more or less become the standard for cloud services.
Amazon S3 and other services
There are cloud services that use a different API, such as Google Cloud, Microsoft Azure and Backblaze B2, but they also provide tools for easy migration from S3.
Google offers tools [2] that are currently only available for Java or Python. And Backblaze has recently added an extra S3 compliant API to their B2 service[3].
We can discern a tendency of convergence towards S3 and while this may or may not be good news, at least it unifies the APIs of some storage providers. However, S3 still is a rather comprehensive API.
Testing with local storage
In addition to the reasons mentioned above (abstraction and simplification), we wanted a tool that made it possible to use storage on a local disk and storage in the cloud interchangeably.
During development, we often use local disk storage to save network calls but we want to be able to seamlessly switch to a cloud service on the production server.
How it works
Our simplified bare-necessity API is defined in a thin wrapper that forwards all API calls to adapters. There is an adapter for every supported storage type (Amazon, Google, Backblaze and local disk) and based on the configuration the appropriate adapter will be used.
The adapters translate the generic API calls to storage specific calls. To make it transparent to the wrapper which adapter is used (necessary for friction-free switching between storage types) the adapters also implement the API methods. This way an API call can be forwarded one-to-one to an adapter, for instance:
async listFiles(numFiles?: number): Promise<[string, number][]> {
return this.adapter.listFiles(numFiles);
}
Another result of this setup is that new adapters can be added very easily, both by ourselves and by others.
Some code examples
You start by creating an instance of Storage. The constructor requires a configuration object or a configuration url. Both configuration options have their pros and cons, it is also a matter of taste:
const config = {
type: StorageType.LOCAL,
directory: "path/to/folder/bucket",
mode: "750",
};
const s = new Storage(config);
// or
const url = "local://path/to/folder/bucket?mode=750";
const s = new Storage(url);
Once you have created an instance, you can call all API methods directly on this instance. Note that most methods return promises:
const files = await s.listFiles();
There are also some handy introspective methods:
s.getType(); // local, gcs, s3 or b2
s.getConfiguration(); // shows the configuration as
// provided during instantiation
And you can even swith between adapters at runtime, this feature is used in the example application:
// local storage
const urlLocal = "local://path/to/folder/bucket?mode=750";
// Google Cloud storage
const urlGoogle = "gcs://path/to/keyFile.json:projectId@bucketName";
// connect to local storage
const s = new Storage(urlLocal);
// switch to Google Cloud storage
s.switchStorage(urlGoogle);
Further reading
The code and extensive documentation are available on Github. Please don't hesitate to drop us a line should you have any questions.
Links to materials used or mentioned in this blogpost:
- [1] Wikipedia about cloud storage
- [2] Google Storage migration from S3
- [3] Backblaze announcing S3 support
- Microsoft announcing S3 support
- Microsoft Azure and Minio sercer
- Using Minio to make Google Storage S3 compliant
- Painting by Jean-Michel Cels (1819–1894) Cloud Study, ca. 1838–42 Oil on cardboard Thaw Collection
- Painters and clouds