Statime continues: Boundary Clocks and Master Ports

After raising new funds for our effort, we were able to start the second phase of the development at the beginning of this year. We've implemented a couple of new features -- two of them, to be exact. We also invested a lot of time in improving the existing implementation.
During this second phase, Tweede Golf started Project Pendulum, the new home of our two time synchronization projects, including a Rust implementation of NTP: ntpd-rs.
![]()
In this blog, we'll go over each of these changes and document the decisions we made along the way.
New features!
Starting with the most exciting changes: statime now supports master mode and boundary clocks. While these additions are not necessarily huge, finding a way to elegantly integrate them into our existing codebase was a challenge.
Master mode
The previous iteration of statime only supported slave mode. This meant that a PTP instance would simply wait for messages from a master to come in through its port, and those messages would instruct it to synchronize its internal clock. This other master would have to run some different program. The current version of statime has no such limitation. It now runs the Best Master Clock Algorithm (BMCA) to determine whether a port is certified to inform other clocks about the most accurate time in master mode, or if it should listen to a more accurate master in slave mode.
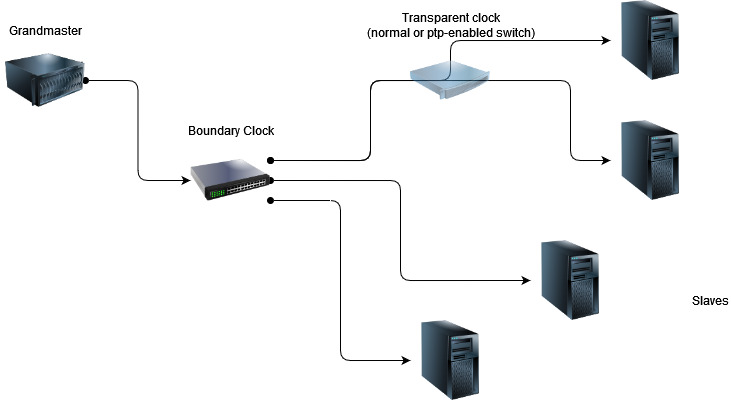
Boundary clocks
Previously, all clocks using statime were 'Ordinary Clocks' (OCs). These clocks have exactly one port to send and receive PTP messages on. This was fine for endpoints with a direct connection to the grandmaster clock, but not all clocks will have that luxury. Boundary Clocks (BCs) can have multiple ports, allowing them to form a network that forwards the best time source to all other clocks.
Implementation-wise, BCs are similar to OCs. Having their own internal time source, a BC can either listen to the best master and synchronize with it, or take on the master role itself, just like an OC. But implementing this properly requires a bit of work. The PTP specification dictates that all ports of a PTP instance run virtually in parallel, each with its own update intervals. Yet, the BMCA algorithm has to stop all of them to determine the new state for each of the ports.
If the BC is the most reliable clock in the network, all ports should be in master mode, and if it's not, exactly one port should be in slave mode, whereas all other ports should forward the most accurate time messages in master mode. Implementing this stop-the-world approach elegantly is a challenge and to make it even more interesting, a prior refactor made a significant part of the codebase asynchronous, and the future that ran a loop on each port happened to be not cancel-safe which clashes with the stop-the-world requirement of the BMCA and the borrow checker.
STM target
Though not a PTP feature itself, the entire library has been made no-std which means it can run pretty much anywhere. And because the ethernet peripheral on many STM32 microcontrollers supports PTP, that was a nice target to try it out on. So now in the statime repo, there's an example project for the STM32F767 running a full PTP stack using RTICv2, stm32-eth and smoltcp. (Initially we wanted to build it on embassy, but stm32-eth uses a different HAL, so we went with RTIC instead.)
Before we could do this we encountered several problems. Because of how STM implements its timestamps, you have to read them from the TX and RX descriptors, and existing drivers didn't support this yet. Another problem we had is that there was no way of correlating a timestamp to a sent or received packet. However, at that time the refactoring of statime was still in full swing, and it was decided to shelve the STM work for the time being.
Fast forward a few months later and to our surprise, both problems had been fixed! So shout-out to community member datdenkikniet for adding packet metadata to smoltcp and for the extensive work on stm32-eth. After that it was smooth sailing, simply implementing the required bits and pieces for statime.
Boundary-clock validation
To validate proper functioning of the boundary clock and the master functionality of ports we ran a number of tests in our lab. In these tests, we used 3 machines, two running as ordinary clocks (A and B) and a third machine running as boundary clock, all running statime-based software. Each of the ordinary clocks was connected to a separate network port of the boundary clock, and they had no direct connection. Furthermore, ordinary clock A was configured with a higher priority for becoming master, whereas ordinary clock B and the boundary clock were configured with the default priorities suggested in the PTP specification.
Our goal with this testing was to observe that the boundary clock and the ordinary clocks would properly change their state in response to changes in the network.
To this end, we initially started only the two ordinary clocks A and B. Since they don't share a network connection we saw that both switched into the master state after an initial startup period. This was expected as neither had another source of time on their network. Furthermore, by observing PPS signals produced by the ordinary clocks we could clearly see they were not synchronized to each other.
Next, we started the boundary clock. We observed that it rather quickly decided to synchronize to ordinary clock A, as it had the higher priority. Furthermore, it started to properly distribute the time to ordinary clock B over the second network interface. Finally, showing that everything worked as expected, ordinary clock B followed with a state change to slave. Beyond these expected state changes of the 3 clocks, we also observed from the pulse-per-second signals of the ordinary clocks that their clocks were now synchronized.
Measurements
Beyond the functional validation described above, we also ran a test aimed at measuring the performance of our PTP and NTP implementations. This focused on a relatively common setup: A GPS PTP grandmaster clock that provides time to an intermediate server that functions as a bridge to NTP, which is then used by client devices to set their system clock.
Our goal was to validate that such a setup could be created with statime and ntpd-rs, and yielded reasonable performance out of the box.
Setup
We use a GPS antenna for our reference time signal. This signal is connected to our grandmaster clock, which both provides a Pulse per Second (PPS) signal and serves as a PTP master clock.
Then we have two raspberry pi devices, A and B. Pi A synchronizes with the PTP master clock, and also runs an NTP server. The NTP server just serves time, it does not synchronize to any external time source. Pi B runs an NTP client. Both pis also provide a PPS signal. Both NTP and PTP clients are running with their default configurations.
We collect the data from all three PPS signals, so we can look at the offsets beteen them. Note that no corrections were made for any asymmetry in the system and that the raspberry pis don't support any hardware timestamping.
Results
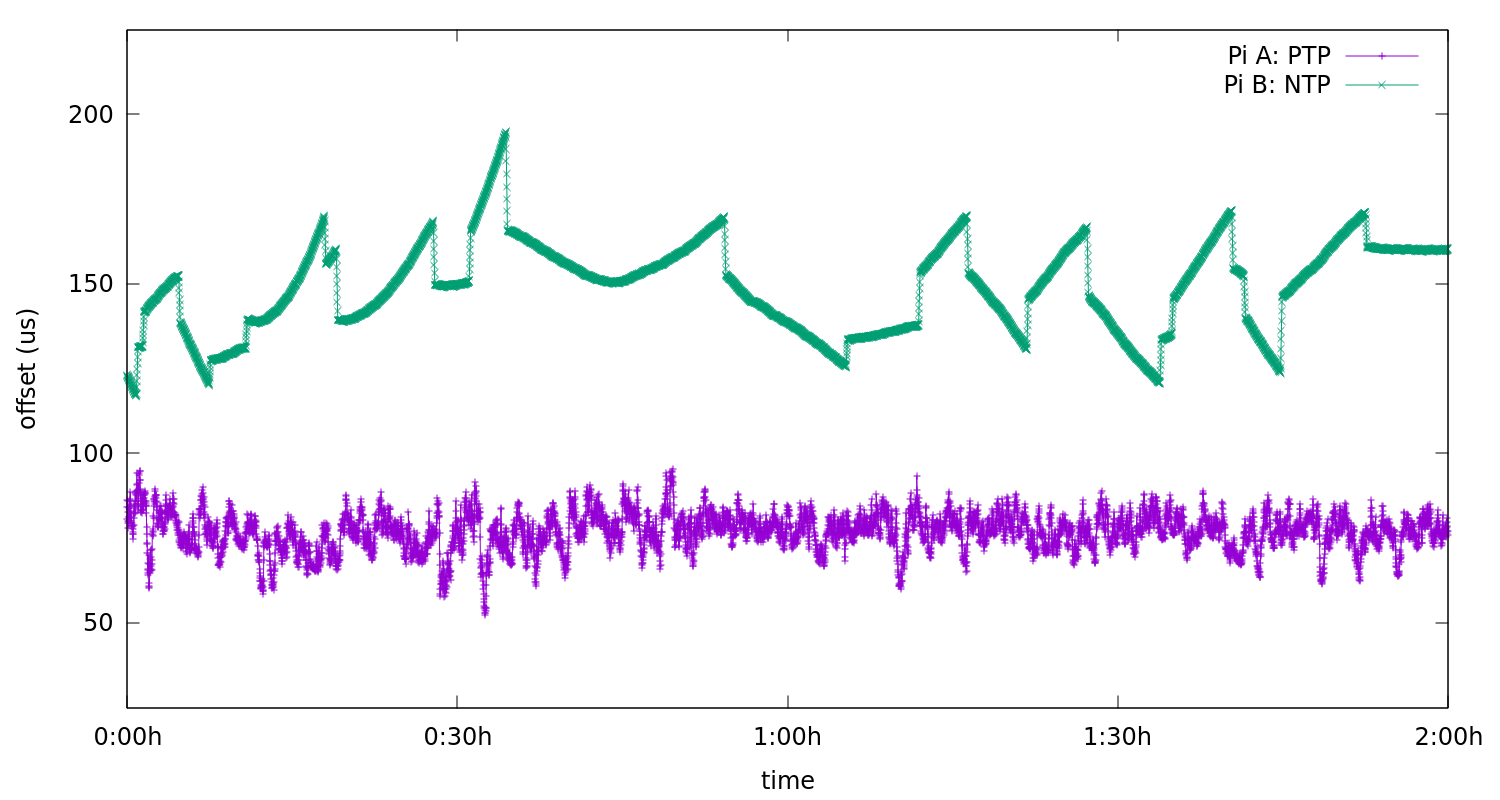
The plot show the offset of the PTP (bottom) and NTP (top) synchronized devices compared to the grandmaster clock. We see a clear difference between NTP, which steers only when detecting a statistically significant offset, and our PTP algorithm, which continuously tries to correct the clock. Both NTP and PTP clients were started well before the start of the data here, and given at least 20 minutes to settle into stable behaviour.
From the data, we can calculate both the average offset and how much variation there is in the offset. The latter we will estimate by calculating the standard deviation of the offsets measured.
| Device | offset | variation |
|---|---|---|
| Pi A (PTP) | 76.8us | 5.5us |
| Pi B (NTP) | 149us | 13us |
This shows a similar picture to the plot above, with significant (but constant) offsets, with a smaller random variation on top of that. The constant offsets are a result of asymmetry in the send and receive paths both at the hardware and software levels. Since they are constant, they could in theory be eliminated by simply telling the clients what asymmetry to expect to their upstream servers. This, in combination with the fact that it cannot be measured "over the network", means that we mostly focus our analysis on variation, as this is much more correlated to actual software performance.
On variation, we see confirmed that the NTP synchronized clock's variation is indeed higher than that of the PTP synchronized clock. However, considering that the NTP implementation effectively receives far fewer measurements (once every 16 seconds instead of once per second) it is performing rather better than one naively would expect. The reason is that we spent much more time on our custom NTP algorithm (based on Kalman filters). We plan to use a similar approach for PTP at some point, which should give a significant gain in accuracy.
Coming up
Moving forward, we are looking to improve the usability of statime for end users. This will involve reworking the API that the library uses to be easier and more flexible to use.
Additionally, we are looking to start providing proper linux binaries, offering an alternative to linuxPTP. Our longterm goal for this is to make this as easy to setup as an NTP server is today.
An up-to-date roadmap can be found in the project's readme.
Thanks to our sponsors
Statime would not be possible without the support of our sponsors. We thank NLnet Foundation and the NGI Assure fund for supporting this phase of our project, see https://nlnet.nl/project/Statime-PTP-Master/.
For statime's upcoming "PTP for Linux" milestone, and further work in 2024, the Sovereign Tech Fund has made a generous investment.
Care to sponsor our work on time synchronisation?
The Pendulum project is building modern, full-featured implementations of the Network Time Protocol and the Precision Time Protocol. Pendulum focuses on security and robustness, and uses the Rust programming language to guarantee memory safety.